Re-scaling the age variable in cross-sectional trajectory analyses
For a cross-sectional trajectory on a single variable for a single group, the age variable (chronological or mental) should be rescaled to count in months from the youngest age measured. This will ensure that the regression equation returns as its intercept (constant) the initial performance level at the start of the trajectory in the age range you have measured. We refer to this in abbreviation as mya or months from youngest age.
Mya:
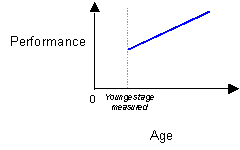
For two or more trajectories corresponding to repeated measures of a single group (Task 1, Task 2, etc.), the age variable should once more be re-scaled to count in months from the youngest age of the group (mya). This allows main effect of task to be calculated at onset.
Mya:
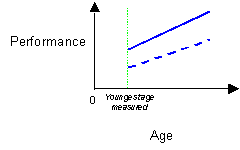
(Alternate re-scalings may be used to test for main effects of Task at different ages. The analyses calculate the Task effect at age = 0. To calculate the main effect of Task at the oldest age measured, age should be re-scaled so that the oldest age = 0 and ages are scored as negative values in months backwards from the oldest age).
For between group comparisons or mixed designs where a disorder group is compared to a typically developing (TD) group, the experiment should normally be designed so that the TD age range spans the chronological or mental age range of the disorder group. That is, all chronological ages or mental ages of the disorder group should fall within the range of the TD group. Where this has been achieved, the age variable should be re-scaled to count in months from the youngest disorder age (or mental age) measured, which we abbreviate to myda. This allows the main effect of group to be calculated at onset with respect to the disorder trajectory you have measured.
Myda:
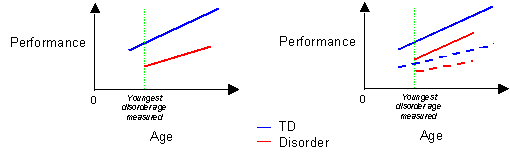
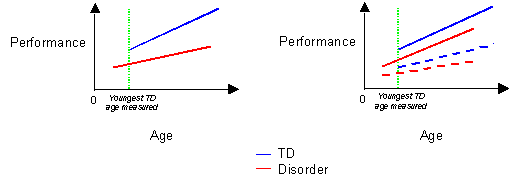
In some cases, the design may have not worked perfectly and the disorder group may exhibit younger ages than found in the TD group (for example, if your disorder sample exhibits unexpected low scores on a given test of mental age). In this case, the re-scaling should be calculated to count in months from the youngest TD age measured (myta).
The reason for this is that the main effect of group or task should always be calculated at the earliest age where the two (or more) trajectories are overlapping. Neither disorder nor TD group should be extrapolated outside of the age range measured when carrying out a task or group comparison. This is because trajectory analyses (unless otherwise stated) are only intended to describe and statistically characterise the patterns in observed data. Predicting performance prior to or following the range measured requires additional assumptions.
Myta:
As we have indicated, our preference is to recruit a typically developing sample that spans the lowest MA of the disorder group to the highest CA of the disorder group. However, this can mean that in the CA-based analyses, the TD and disorder trajectories do not overlap for the youngest TD participants, while for the MA-based analyses, the trajectories do not overlap for the oldest TD participants. The re-scaling procedures above ensure that group differences (i.e., differences in intercepts) are calculated at a point where the trajectories do overlap. One consideration is whether one should in fact exclude data from trajectory comparisons whenever the trajectories do not overlap. For instance, one might exclude the youngest TD participants for the CA comparison, and the oldest TD participants for the MA comparison.
In our view, the full TD sample should be retained except where the inclusion of non-overlapping participants compromises the linearity of the TD trajectory. If the trajectory is linear across the TD age range, the largest number of TD individuals should be included to maximise the validity of the sample as representative of typical development and to maximise statistical power. However, if TD participants at points of non-overlap of the TD and disorder trajectories are compromising the linearity of the TD trajectory - in other words, altering the gradient of the TD trajectory across the age range where that trajectory does overlap with the disorder sample - then these TD participants should be excluded and the analyses re-run.
Reader Query
Question: I have been thinking about using Test of Receptive Grammar (TROG) raw scores instead of mental age equivalents to plot metaphor and metonymy performance against grammatical ability in typically developing children and children with a developmental disorder. Now when you use raw scores and you want to calculate MYA and MYDA, do you subtract each raw score with the lowest raw score of the group (for MYA) with lowest raw score of disorder group (for MYDA)? Or is there no need for this when you use a standardardised task as an experimental task?
Answer: Visualise your trajectories on a plot. Presumably you will have 4 trajectories here, 2 for TD (metaphor, metonymy) and 2 for your disorder group.
When you just throw in data where you haven't scaled the predictor (be it raw scores or test ages or performance on some other test), the trajectory analysis will spit out main effect results (the ones excluding the predictor/covariate). These will be things like the group effect, or the task effect, or the group x task interaction.
The crucial point here is that the trajectory analysis is doing the comparison between the lines at the point when the value of your predictor is ZERO. I.e., age = 0, raw score = 0, experimental score = 0, reaction time = 0, etc.
In a lot of cases, it makes no theoretical sense to compare the intercepts (height) of the lines when the predictor is zero. Age can't be zero. Reaction time can't be zero.
However, we are committed by the way the stats works to compare the height of the lines when the score is zero (the intercept of a line y = ax + b definitionally has intercept b when x = 0).
This is the point of rescaling. Let's change zero to be something more meaningful.
In the trajectory framework, we differentiate the performance level at onset, and the subsequent rate of development. So it makes sense to rescale the predictor to make zero equivalent to the first point of overlap of the trajectories of the two groups.
I think that translates to the following: Assuming the higher the raw score, the better the performance, then if TD raw scores span A to B and disorder raw scores span X to Y, find out which is higher, A or X. Whichever number is the larger is the first point of overlap of the ranges.
If it's A, subtract A from all the raw scores (equivalent to MYA). If it's X, subtract X from all the raw scores (equivalent to MYDA). The rescaling will ensure you are comparing main effects at the point of first overlap of the TD and WS trajectories.
© Michael Thomas 2009
Lasted edited 06/10/09